GDPR Privacy
Nuove minacce privacy: il ruolo dell’IA nello svelare identità online
L’ascesa dei LLMs (Large Language Models) come GPT-4 ha dato il via ad una nuova era di abilità tecnologiche, grazie anche alla loro immensa capacità di memorizzare e dedurre informazioni; il che solleva forti preoccupazioni sotto il profilo privacy, perché queste caratteristiche permettono a tali sistemi di compiere inferenze sui dati fino ad identificare una specifica persona fisica da informazioni apparentemente innocue.

Come indica la didascalia della foto, ecco i dati sulla "Accuracy" di vari LLM nel dedurre attributi personali dai testi rispetto alle abilità di una persona - credits: https://llm-privacy.org/
Il problema di fondo della memorizzazione dei dati
Gli LLM hanno la capacità intrinseca di memorizzare ed elaborare set di dati davvero estesi, che spesso includono informazioni potenzialmente sensibili. Questa capacità si estende alla deduzione di attributi personali dell’utente anche da una serie di testi non strutturati, come un semplice commento o un post su un social media.
Le implicazioni sono di portata enorme: semplicemente analizzando i post online di un utente, gli LLM possono estrarre informazioni private che gli utenti non avrebbero mai avuto intenzione di divulgare.
Gli LLM non elaborano semplicemente le parole; sono maestri del contesto, del tono e delle sottili complessità del linguaggio umano. Ciò significa che anche quando pensiamo di essere solo un altro nome utente senza volto in un forum o quando commentiamo liberamente su un blog, questi modelli raccolgono su di noi molte più informazioni di quanto ci possiamo aspettare.
Consideriamo un utente che commenta sui social la partita vinta dalla sua squadra del cuore, menzionando chi ha segnato con uno slang tipico della sua terra natale. Sebbene l’intenzione non fosse quella di rivelare la propria posizione, un LLM può dedurre da questi sottili indizi la localizzazione dell’utente. E questo è uno solo dei tanti esempi che potremmo fare, sulla scorta di quanto hanno recentemente pubblicato alcuni ricercatori, mettendo in evidenza questo problema di “identification” dell’utente, e quindi di violazione della sua privacy.
Violazioni che possono poi condurre a potenziali abusi come campagne politiche mirate al singolo utente (Cambridge Analytica dovrebbe averci insegnato qualcosa…), profilazione automatizzate, stalking e l’elenco potrebbe continuare perché, purtroppo le potenzialità sono enormi.
Questo è dovuto anche alla scalabilità e facilità con cui è possibili, per agenti malevoli, eseguire inferenze utilizzando tali modelli. È possibile raggiungere obiettivi di larga scala con sforzi e costi minimi (vedi il seguente grafico).
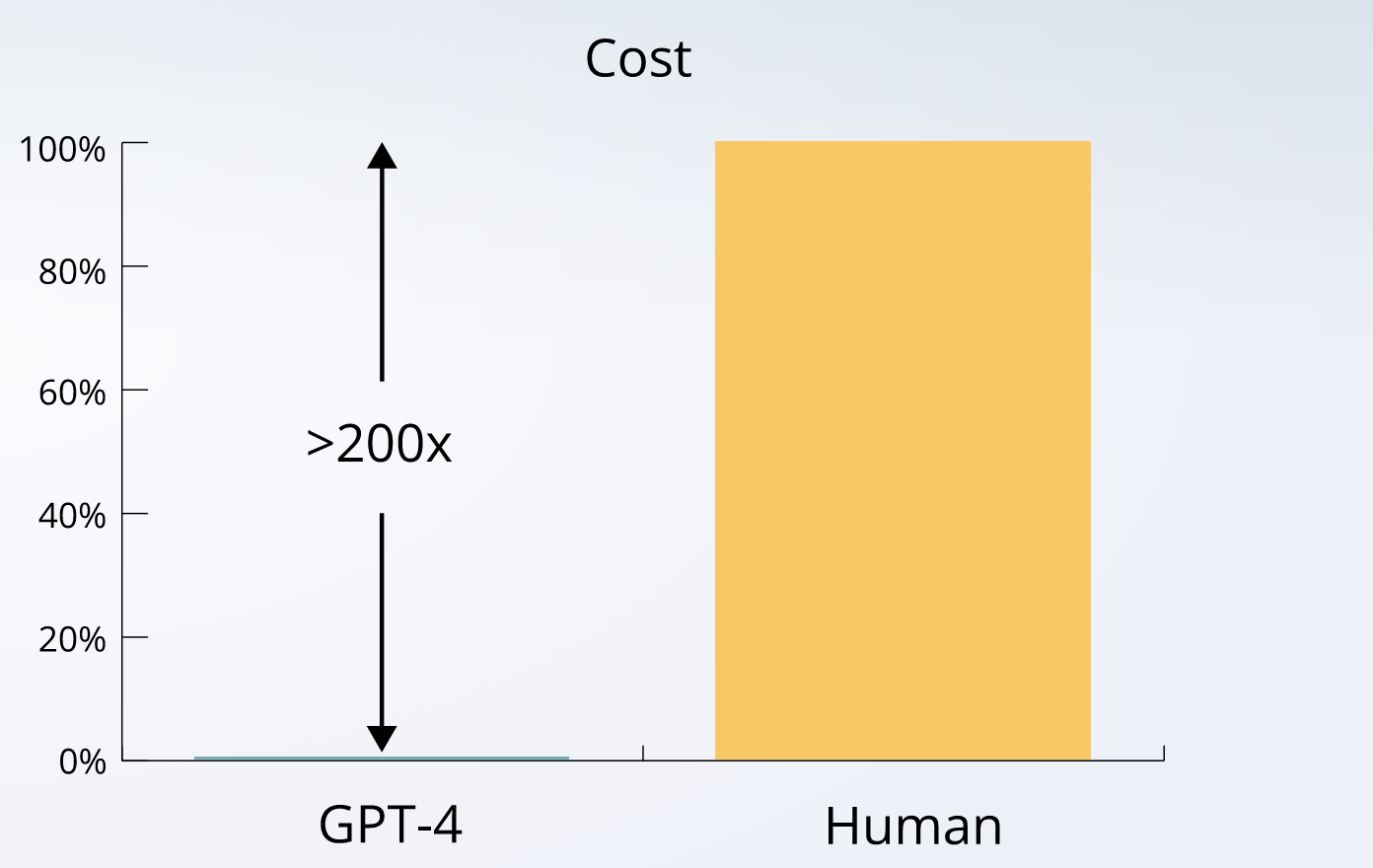
Un altro dei pericoli è dato dalla grande scalabilità dell'AI che permette di compiere azioni di "identificationi" con sforzi e costi minini.
Anonimizzazione: una soluzione parziale
Per mitigare questi rischi, esistono strumenti che hanno l’obiettivo di rendere anonimo il testo prima che venga elaborato dai LLM, rimuovendo informazioni identificabili come posizioni, nomi e date. Tuttavia, la ricerca mostra che anche con strumenti di anonimizzazione all’avanguardia, la precisione di GPT-4, il più potente nel dedurre informazioni private, diminuisce solo marginalmente. Ad esempio, in termini di geo-localizzazione, la “accuracy” del modello scende dall’86% a circa il 55%, una riduzione tutt’altro che ideale per un testo che si dovrebbe definire anononimo!
Gli esperimenti indicano che gli attuali LLM non sono sufficientemente pronti per contrastare questa minaccia, perché il c.d. safety allignment del modello si concentra su elementi di sicurezza in termini ad esempio di violenza, discriminazione, ma non di privacy (se vuoi approfondire, ne abbiamo parlato già qui).
Durante i test con diversi modelli, si è osservato che loro il tasso di richieste rifiutate per motivi di privacy è relativamente basso. Per cui se l’utente chiede o fornisce informazioni che rivelano aspetti molto personali della sua identità, il modello generalmente non attiva dei filtri di protezione, evitando di “ingaggiare” una conversazione, ma prosegue nella conversazione.
I modelli PALM-2 di Google, per fornire un esempio a tal riguardo, mostrano un tasso di rifiuto del solo 10,7%.
La precisione relativamente elevata nel dedurre informazioni personali da un testo “anonimo” solleva quindi interrogativi sulla conformità di questi sistemi alle normative sulla protezione dei dati, oltre a sollevare temi di responsabilità legale per chi sviluppa o, in qualche modo, immette sul mercato tali modelli. L’attenzione della ricerca sui filtri di sicurezza per questi sistemi (c.d. safety alignment), dovrebbe dunque al più presto includere anche le possibili violazioni di privacy dell’utente. Le vulnerabilità accertate sotto questo profilo sono ad oggi davvero allarmanti.
Articoli correlati